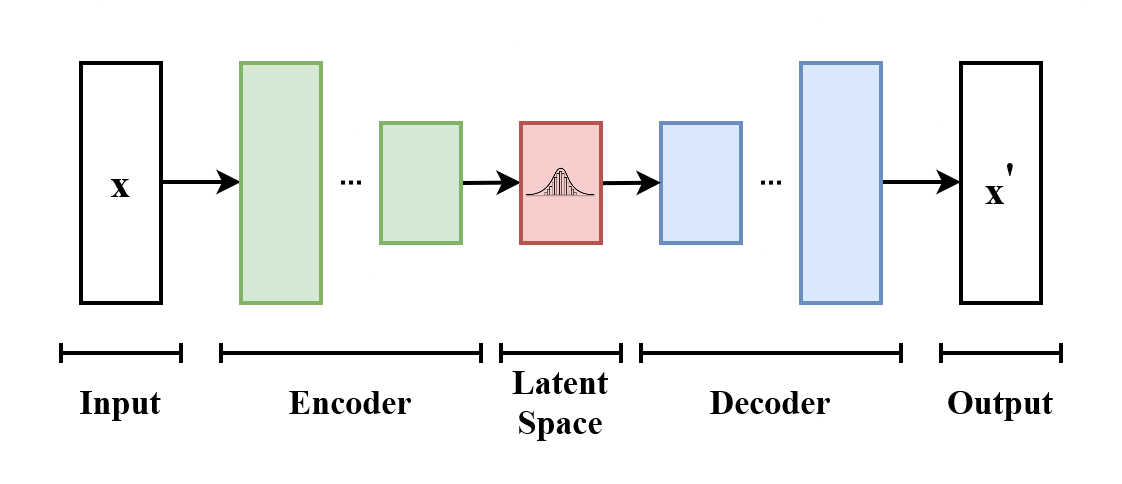
Abstract: How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions are two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results.
We recommend that you at least take a quick look at the article:
KINGMA, Diederik P.; WELLING, Max. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
https://arxiv.org/abs/1312.6114
Who: Antonie Brožová
When: 10:00 a.m. Friday, March 22
Where: The session will occur physically at the Institute of Information Theory and Automation (UTIA). Depending on the number of listeners in room 25 or 45 (café). For directions to the institute, please refer to the following link: https://www.utia.cas.cz/contacts#way
Language: Czech (if you require English, please let us know in advance)
Zoom: https://cesnet.zoom.us/j/95065281700


